当你拥有一台 kindle 后,你会干嘛?单纯的阅读 or 看漫画? no!no!no!
使用 kindle 半月后小小心得。
电子书
kindle 的优势不在于墨水屏,市面上已经有非常多的电纸书产品。kindle 有庞大的亚马逊作为支持,从书籍数量到书籍内容,亚马逊提供了完美的 kindle 生态链。
利用 kindle 带来的沉浸式阅读体验,带来与纸质书一样的深度阅读。
如何寻找电子书资源?
百度?可以,但是比较复杂,往往得不到自己想的东西。那么我是如何寻找电子书资源呢?
利用 Chrome 的油猴插件,使用 豆瓣资源下载大师:1 秒搞定豆瓣电影-音乐-图书下载 — kod źródłowy
【装这一个脚本就够了!可能是你遇到的最好的豆瓣增强脚本】聚合数百家资源网站,通过右侧边栏 1 秒告诉你哪些网站能下载豆瓣页面上的电影-电视剧-纪录片-综艺-动画-音乐-图书等,有资源的网站显示绿色,没资源的网站显示黄色,就这么直观!所有豆瓣条目均提供在线播放-阅读、字幕-歌词下载及 PT-NZB-BT-磁力-百度盘-115 网盘等下载链接,加入官网打死也不出的豆列搜索功能,此外还能给豆瓣条目额外添加 IMDB 评分-IMDB TOP 250-Metascore 评分-烂番茄评分-AniDB 评分-Bgm 评分-MAL 评分等更多评分形式。
在豆瓣里找到你想要的资源,在侧边栏里会出现很多选项,显示绿色表示有资源。减少在百度上的时间,当然,如有条件请支持正版。
漫画
漫画资源 [Vol.moe] Kindle 漫畫
RSS
Reabble 利用 kindle 自带的「体验浏览器」,打开 reabble.com 在 kindle 端体验 RSS 阅读的快感。
Reabble 是 Kindle 上的 RSS 新闻阅读器,专为使用电子墨水屏的浏览器设计交互界面,媲美系统原生阅读体验。 也能用于其它带浏览器的设备比如手机、Nook、Kobo、博阅等。
Reabble 的优势在于完美适配 kindle,免费版一天只能看 7 篇文章,开通会员则没有限制,会员 26 一年。还是比较实惠,你也可以试用,体验后再决定要不要开通会员。
博客
利用 calibre 爬取博客文章,在 kindle 阅读。在 calibre 中你可以编写 Recipe 脚本,利用脚本爬取博客内容,实现自动获取你想要的文章。
Recipe 脚本模板
#!/usr/bin/python
# encoding: utf-8
from calibre.web.feeds.recipes import BasicNewsRecipe # 引入 Recipe 基础类
class yang_zhi_ping_Blog(BasicNewsRecipe): # 继承 BasicNewsRecipe 类的新类名
#///////////////////
# 设置电子书元数据
#///////////////////
title = '阳志平的网志' # 电子书名
description = u'阳志平的网志' # 电子书简介
#cover_url = '' # 电子书封面
#masthead_url = '' # 页头图片
__author__ = '阳志平' # 作者
language = 'zh' # 语言
encoding = 'utf-8' # 编码
#///////////////////
# 抓取页面内容设置
#///////////////////
keep_only_tags = [{ 'class': 'page_title' },{ 'class': 'page_content' }] # 仅保留指定选择器包含的内容
#remove_tags = [{'class':'explorer'}] # 清除无关标签内容
no_stylesheets = True # 去除 CSS 样式
remove_javascript = True # 去除 JavaScript 脚本
#auto_cleanup = True # 自动清理 HTML 代码
delay = 5 # 抓取页面间隔秒数
max_articles_per_feed = 999 # 抓取文章数量
simultaneous_downloads = 5 #线程数
#///////////////////
# 页面内容解析方法
#///////////////////
def parse_index(self):
site = 'https://www.yangzhiping.com/psy/' # 页面列表页
soup = self.index_to_soup(site) # 解析列表页返回 BeautifulSoup 对象
links = soup.findAll("h2",{"class":"archive__item-title"},{"itemprop":"headline"}) # 获取所有文章链接
articles = [] # 定义空文章资源数组
for link in links: # 循环处理所有文章链接
title = link.a.contents[0].strip() # 提取文章标题
url = link.a.get("href") # 提取文章链接
a = {'title': title , 'url':url} # 组合标题和链接
articles.append(a) # 累加到数组中
ans = [(self.title, articles)] # 组成最终的数据结构
return ans # 返回可供 Calibre 转换的数据结构
第一步
找到你想爬取的博客,这里以阳志平老师博客为例。
- 找到文章列表页,阳老师的文章大部分都在随笔分类随笔合集 - 阳志平的网志 ,我们把 site 参数设置为 https://www.yangzhiping.com/psy/ ,
soup = self.index_to_soup(site) # 解析列表页返回 BeautifulSoup 对象这里参数为目录页,脚本会爬取该参数对应网页内容。
第二步
确定在目录页中博文标题与链接
- 利用审查元素,快捷键 F12 分析文章列表内容。


能看到文章的链接与标题均包含在 h2 标签中
- 我们在 soup.findAll 选择
links = soup.findAll("h2",{"class":"archive__item-title"},这样只会将我们需要的部分爬取下来。
第三步
得到你想要的博文
- 得到文章标题和文章链接后,在来看文章页面内容。
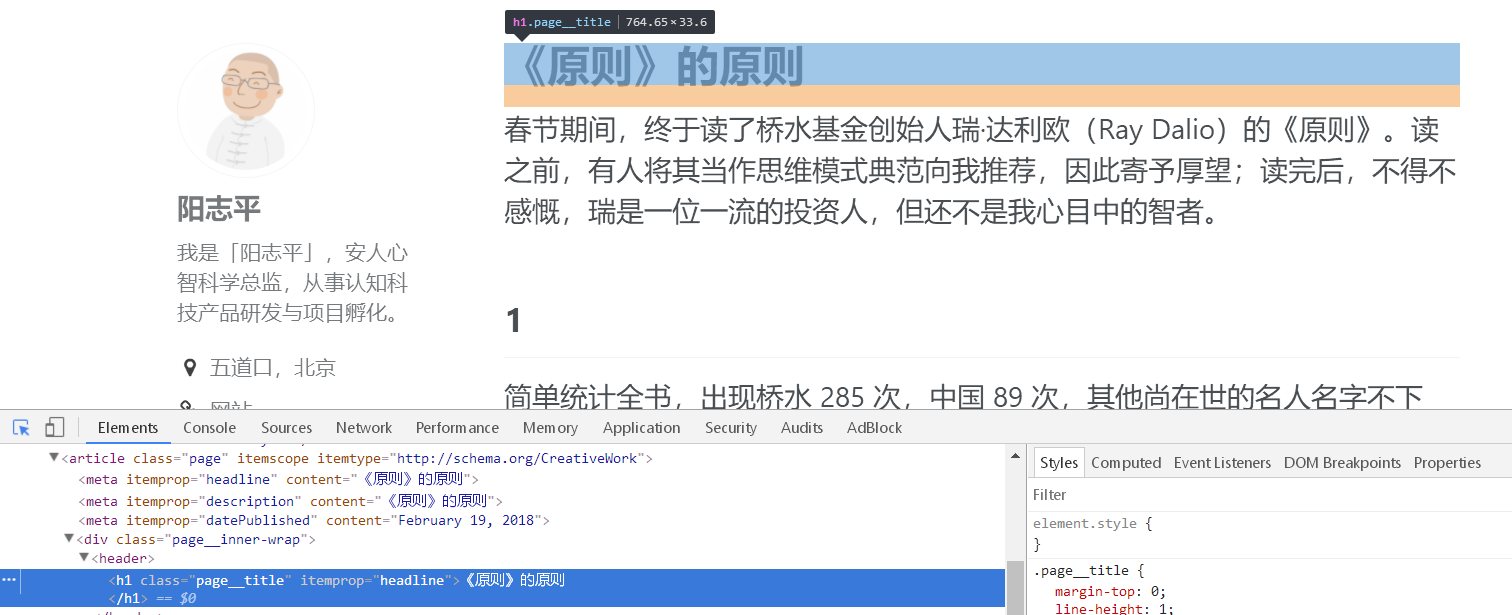
- 这里能看到文章标题包含在 class:page_title 中
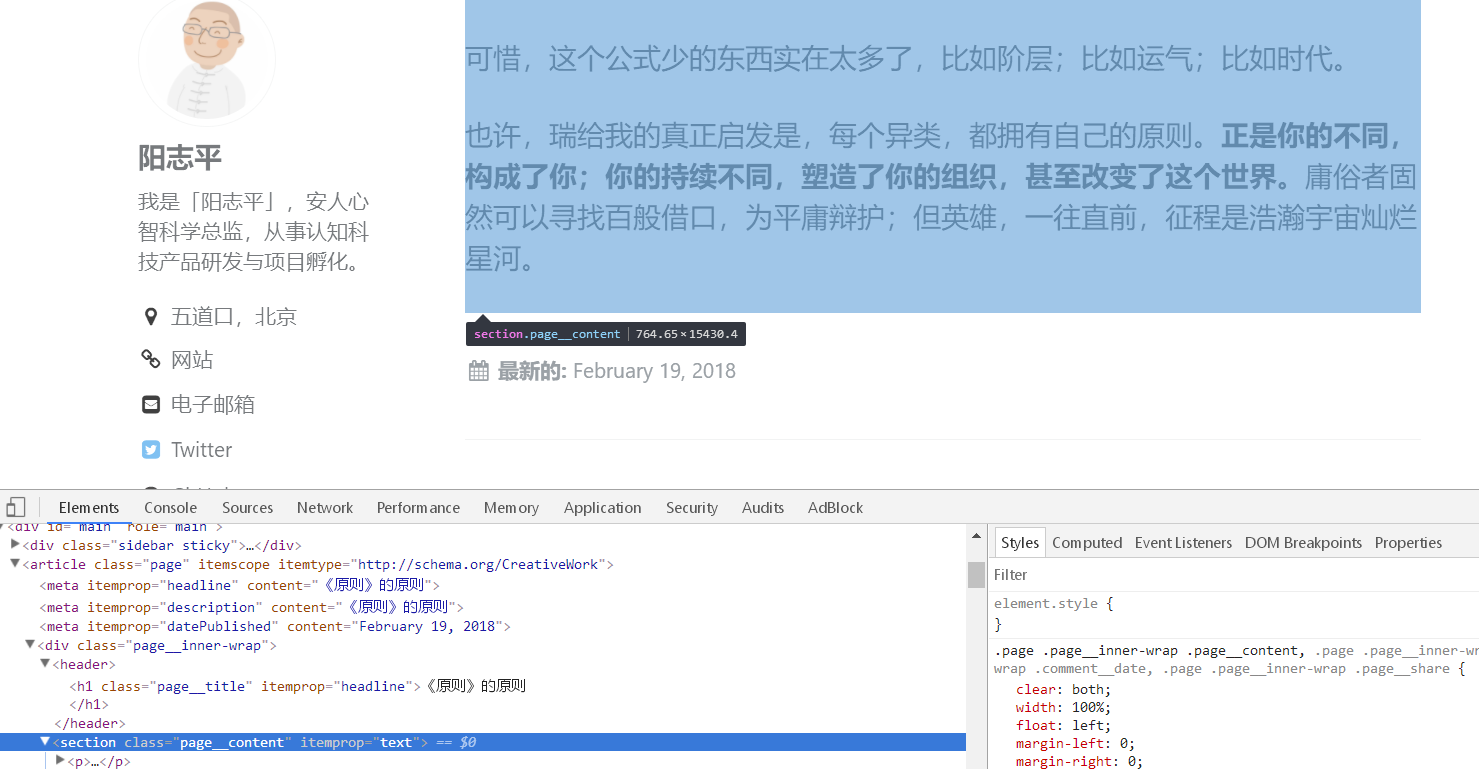
- 文章本体包含在 class:page_content 中。
keep_only_tags = [{ 'class': 'page_title' },{ 'class': 'page_content' }] # 仅保留指定选择器包含的内容 该参数,保留文章本体中需要的部分。如果出现你不想要的,如「下一页」,你可以找到该标签,用 remove_tags 清除无关内容。
第四步
爬取文章,导出为 mobi,这一步由 calibre 自动完成。
小结
总结一下,你需要修改的参数为
- soup = self.index_to_soup(site) 确定博客目录页
-
links = soup.findAll 在目录页确定文章标题与链接所在的标签
- keep_only_tags 你要保留正文内容
- remove_tags 你要清除与正文无关内容
爬过的坑
如果你能爬取文章,但显示没有内容,则表示你 links = soup.findAll 参数找得不对。
如果你能爬取文章,但目录显示未知,则表示你 title = link.a.contents[0].strip() 参数有问题,这个问题我也没有好的解决方案,可以尝试改为 title = self.tag_to_string(link)
如果你能爬取文章,目录正常,但显示不了文章、标题或者多了不想要的地方,则表示 keep_only_tags、remove_tags 这两个参数选取有问题。
参考
ChangeLog
- 2018-09-05 成文
- 2018-09-04 创建