简单的网页爬虫与转换为 PDF
思路
如何将网页转换为自己想要的 PDF 文件?
爬虫的基础思路三步走
- 获取数据
- 解析数据
- 保存数据
在本次实操中分为以下步骤:
- 获取网页的链接
- 查看网页的 HTML 内容,找到想要的部分
- 爬取网页,得到网页内容
- 将爬取的内容转换为转换为 PDF,并保存在本地
实操
1. 确定爬取页面
找到想要的网页,以微软官网提供的 Excel 函数解释页面为例。
网页链接为ABS 函数 - Office 支持
2 . 选取需要爬取内容
查看页面 HTML 内容,找到想到内容。
打开网页后,我想要的只有标题以及说明、语法、实例这些内容。不需要其他的帮助内容。
按下 F11 或右键检查元素,再按下 Ctrl + Shift + C,选择「ABS 函数」。即可看到内容被包裹在class=rocpArticleTitleSection中,也是这个页面的标题。
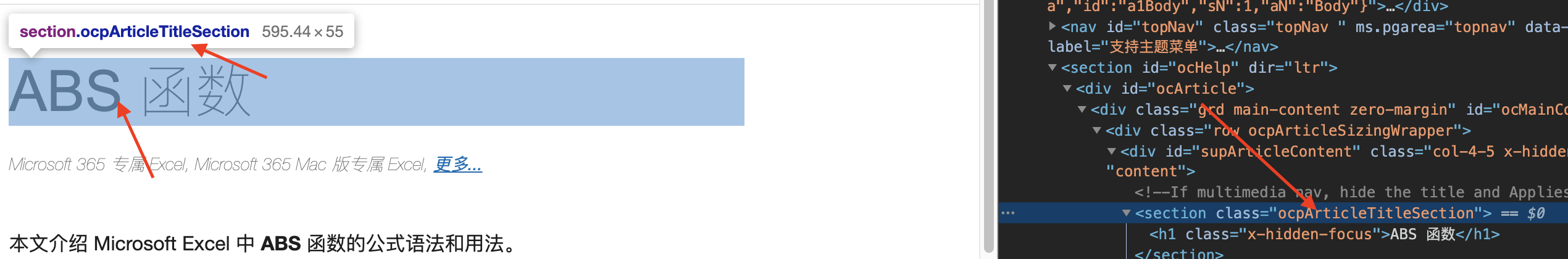
选择说明部分,看到内容被包裹class=ocpArticleContent中,也是页面的主要内容。
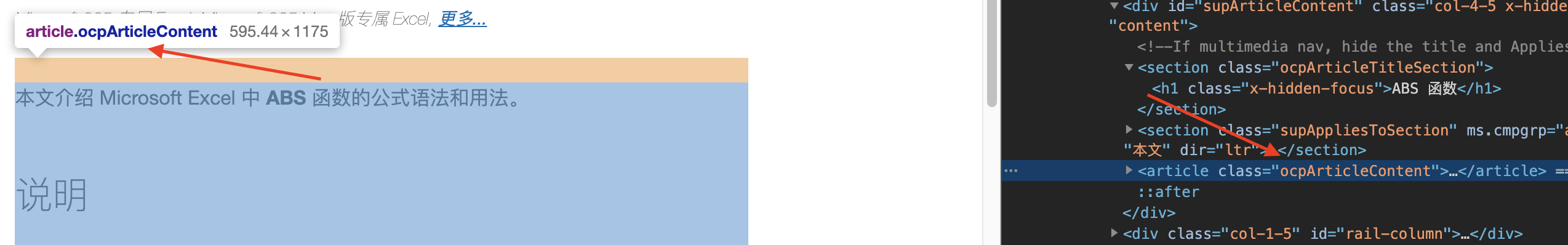
以上两个部分则是我们需要的内容。
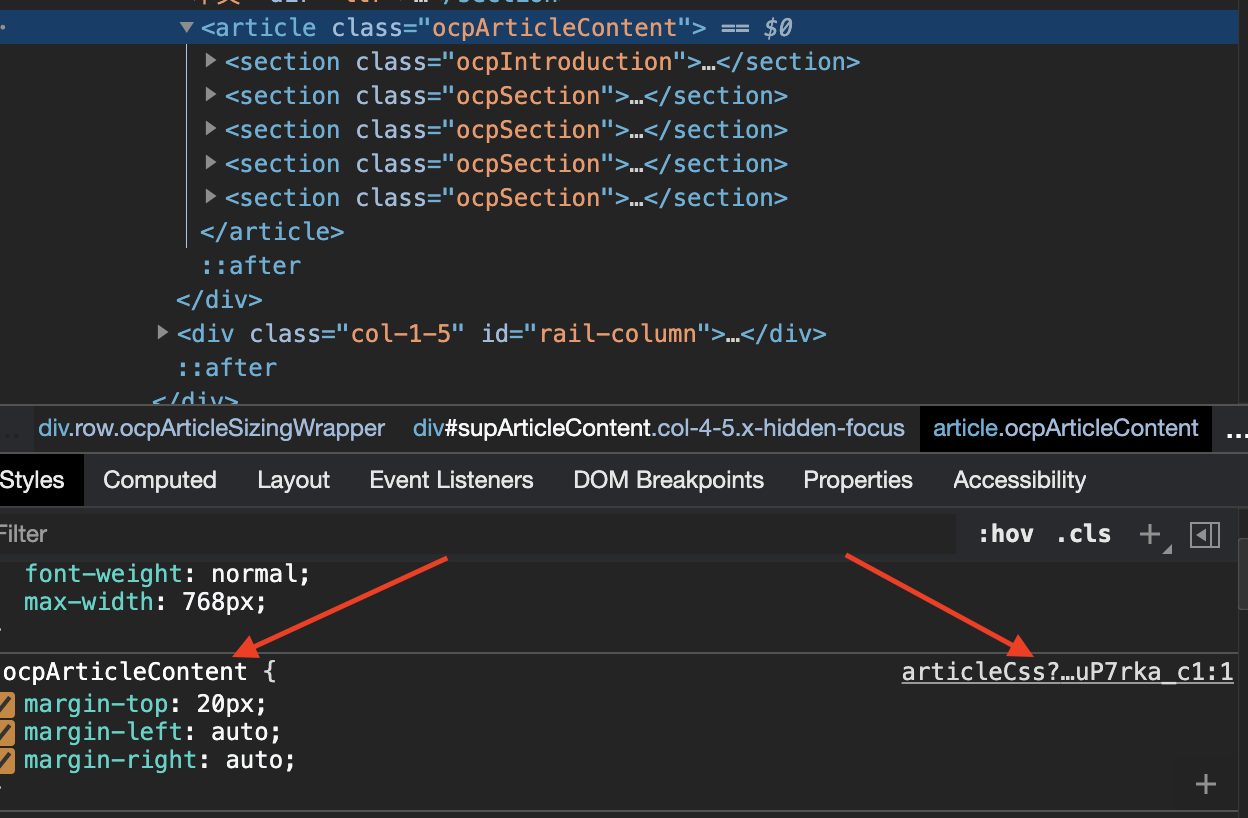
获取的 PDF 的样式,不然内容只有文字,表格无法显示完全。依旧是按下 Ctrl + Shift + C,在下图显示文本样式,点击右边的 artcilteCss。然后全选 1 列内容,复制后保存为 pdf.css 文件。

3 . 编写代码
本次使用环境说明:
- Python 3.7.3
- macOS 11.1
- 需安装 requests、BeautifulSoup、pdfkit 包。安装方式 pip install 包名,如 pip install requests。
- pdfkit 则需先安装wkhtmltopdf软件。
准备工作
import requests
# 导入「发送请求,得到网页所有数据」包
from bs4 import BeautifulSoup
# 导入「解析网页内容」包,得到自己想要的内容
import pdfkit
# 导入「将内容转换为 PDF 格式」的包
pdf_dir = '/Users/xxx//pdf/'
# 保存文件的目录
url = 'https://support.microsoft.com/zh-cn/office/abs-%E5%87%BD%E6%95%B0-3420200f-5628-4e8c-99da-c99d7c87713c'
# 爬取网页的链接
html_template = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
{content}
</body>
</html>
"""
# 创建一个 HTML 的模板
获取网页信息
page = requests.get(url) # 获取链接中的网页内容
解析网页,获取想要内容
soup = BeautifulSoup(page.text, 'html.parser')
# 解析获取的网页 HTML 内容
title = soup.find(class_="ocpArticleTitleSection")
# 获取 HTML 中 <class=ocpArticleTitleSection>的内容,为标题
content = soup.find(class_="ocpArticleContent")
# 获取 HTML 中 <class=ocpArticleContent>的内容,为内容
body = str(title) + str(content)
# 将标题与内容合在一起
html = html_template.format(content=body)
# 将标题与内容和在 HTML 模板中,构建成一个完整的 HTML 文件
将获取的内容转换为 PDF
options = {
'page-size': 'A4', # 纸张大小
'margin-top': '0.75in', # 上边距距
'margin-right': '0.75in', # 左边距距
'margin-bottom': '0.75in', # 下边距距
'margin-left': '0.75in', # 右边距
# 'orientation':'Landscape',#纸张方向横向
'encoding': "UTF-8", # 字符编码
'no-outline': None,
# 'footer-right':'[page]' 设置 页码
}
# 设置转为 PDF 后的页面参数
css = pdf.css
config = pdfkit.configuration(wkhtmltopdf = '/usr/local/bin/wkhtmltopdf')
# 指定 wkhtmltopdf.exe 所在的路径(必须手动设置,不然会报错)
pdfkit.from_string(html, pdf_dir+title.get_text().strip()+".pdf", css=pdf.css, options=options, configuration=config)
# 将获取 HTML 文件转换为 PDF,命名为获取的标题名,保存在制定目录下
参考
- Python - pdfkit - 听雨危楼 - 博客园
- Beautiful Soup 4.4.0 文档 — Beautiful Soup 4.2.0 中文 文档
- 快速上手 — Requests 2.18.1 文档
ChangeLog
- 210122 创建